本文转载自: FPGA的现今未微信公众号
存储器是FPGA设计中的常用单元,对存储器的操作,最基础的就是读写操作,还有一种就是读改写操作,即先读出存储器中的数据,对其进行修改后,再写入存储器。这样的操作其实在大多数情况下都是非常简单的,不值一提,但是在某些有性能要求的场景下,就需要一些考虑。
比如输入是一个8bit的数据,取值为0-255,求每个数值出现的次数,即同时0出现多少次,1出现多少次……
读改写的问题
我们先以最简单的例子,对FPGA内部的RAM进行读改写操作,看看是什么情况,假定需要对RAM中的数据读出来加1后再写回原地址,如下图所示:
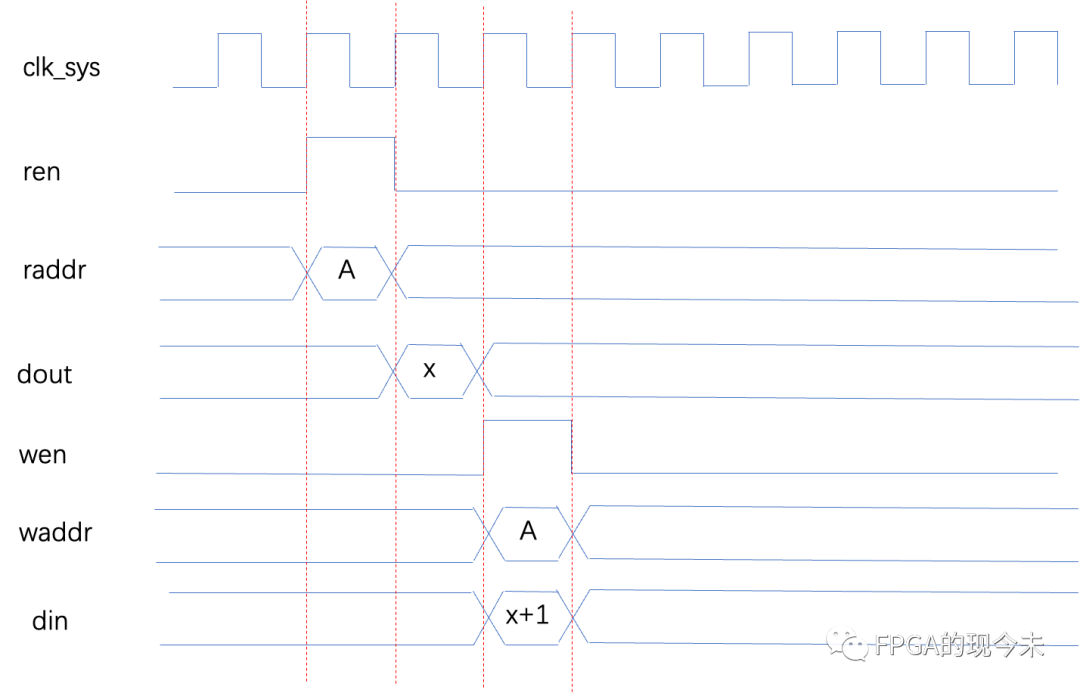
通过读地址A,在下一个cycle得到数据X,然后对X进行加一操作后,再写回地址A。我们可以看到,整个过程需要3个cycle的时间。如果再对地址A开启读操作,就需要在第四个cycle开始,否则就读不到最新的数据。换句话说,上述操作无法进行流水操作,每次读改写操作至少需要3个cycle的时间(对于其他更加复杂的“改”操作,可能需要消耗更多的时间)。对于性能要求较高的场景,必须要流水操作的时候,如何处理呢?
解决方案
我们知道不能流水的原因是因为最新的数据可能没有写回RAM,还在数据总线上,因此判断最新的数据在哪里就是解决这个问题的关键。这里还需要用到一个“cache”,用reg来实现,主要是记录即将要写入RAM的地址和数据,即记录写总线上的地址和数据。其实现原理可以用一个时序图来展示。
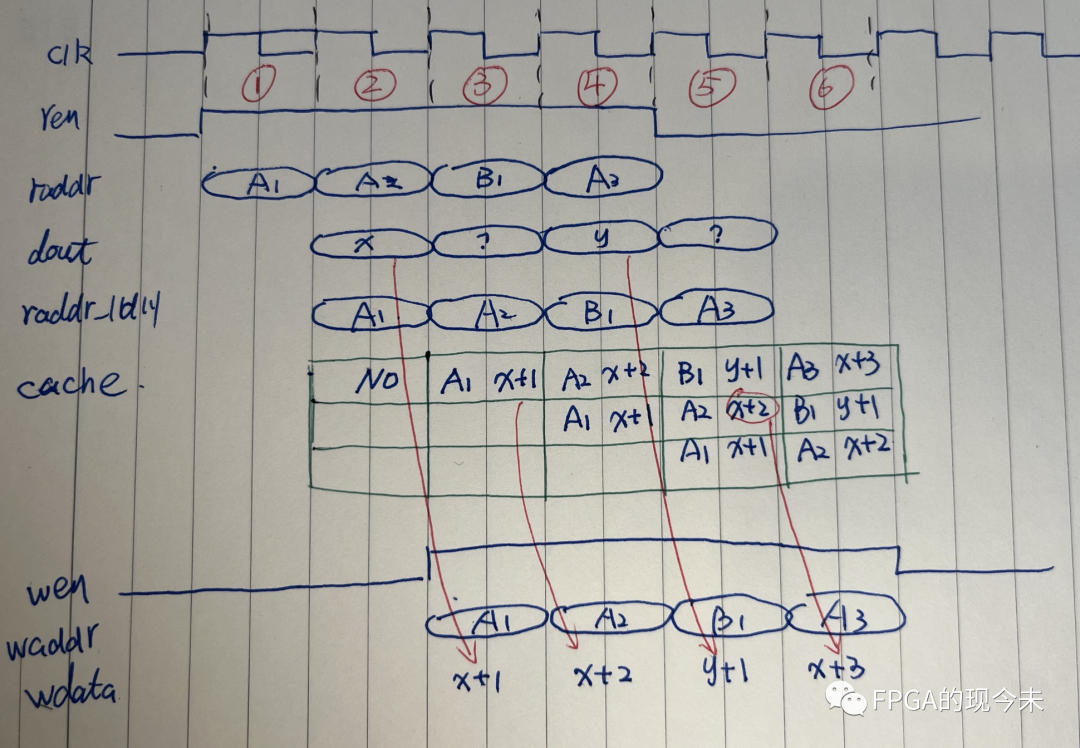
我们假定要读的地址是AABA,但是为了区分,我们用A1、A2、B1、A3来表示(A1、A2、A3其实是同一个地址)。我们看看如何利用“cache”实现流水式的读改写操作。
第1个时钟周期,读A1的内容,此时cache的内容也为0;
第2个时钟周期,A1的内容在dout上,为x,我们同时拿A1这个地址去“cache”查询,由于“cache”为空,不取“cache”中的值,直接取dout上的值作为改写的对象;同时也开始读A2的内容;
第3个时钟周期,主要做2个更新,一是根据第2个周期中出现的A1和dout的值,更新到“cache”中,二是将更新的数据和地址放在写总线上,这2个更新的内容其实是一致的,都是改和写的过程;同时拿A2去查询“cache”;
第4个时钟周期,根据查询的结果,例子中为“cache”命中,选择“cache”中的内容x+1为改写对象,而不是dout上读取的值,所以写入的内容为x+2。同时根据第三个时钟周期中的A2来更新cache,将A2和对应写入的值x+2更新到“cache”中,此时“cache”中有2个内容,一个是A1和值x+1,一个是A2和值x+2;
从第4个时钟周期可以看到,读A2这个地址得到的值,不是从dout上获取的,而是从“cache”中获取的,这就是利用“cache”来实现读改写的流水操作。
在第5个时钟周期,用A3去查询“cache”时,“cache”中有2个A,即A1和A2,这时我们去最“新”的A,即A2的值x+2作为改写对象。
总结
在高性能的读改写场景下,利用“cache”可以实现读改写的流水操作,大大提高了处理性能。当然如果输入的数据并不是流水的,采用最简单的方式实现读改写即可。









